September 1st-15th
As of posting this, I’ll be back to school in a 6 course term. This means that my time for competitive programming in the next four months is limited at best, and with the “contest” that occurred at the end of August, I need to make every contest count to return to CM (1900 ELO).
Round 818
Problems Solved: A, B, C, D
New Rating: 1880 (-3)
Performance: 1868
I’m not sure if I’m being too hard on myself, or it’s been a poor mentality I’ve recently been having, or both, but even though this is statistically the 8th best contest I’ve had, I’m still not happy with this result. Yes, I solved A through D, but Problem C should not have taken 38 minutes to solve. The 38% clear rate it had puts it on the easier end of C problems, and I spent an egregious amount of time stumbling by overcomplicating my attempted solutions. Mainly, I was trying to find how to turn array A to array B when what I should’ve been doing was determining if it was possible to turn array A into array B. These two ideas are clearly different. For instance, if I asked you to determine if 987.83979*202.100971503 > 1000 is true, you would use common sense/basic estimation to determine that the answer is “yes”. What you would not do is manually take out a piece of paper and start creating abstract art in the name of “common core multiplication” to determine the exact value, then compare that to 1000. Solve only what the problem requires you to solve.
Then we go to Problem D. I’ll give credit to myself for figuring out the solution because noticing how Pascal’s triangle is involved with this problem is actually well done. I’ll also excuse myself for the unsuccessful hacking attempt I desperately made since the benefits of potentially passing 92 other coders was worth the risk of dropping 32 places. What cannot be excused is how I had 4 wrong submissions for this problem.
Note: originally I was going to excuse the first wrong submission because I was unsure why it inexplicably failed on test case 8. It is now 6 hours after the contest and put simply, I’m just sad now. The next paragraph may contain excessive amounts of salt.
The first submission fail can be described as follows:
Let a = 2, b = 5, c = 3
My line of code: a = a + b % c
What I assumed would happen:
a = (2 + 5) % 3 = 7 % 3 = 1
What ended up happening:
a = 2 + (5 % 3) = 2 + 2 = 4
Yeah, instead of failing due to not being able to count to five, now I only failed due to 7th grade mathematics. I assume that’s when modular arithmetic is introduced. Oh but wait! What about the other wrong submissions? Number 2 I thought my factorial algorithm that I took directly from my competitive library was bugged so I increased the memory allocated for no reason, EVEN THOUGH I already did extensive testing to confirm the algorithm was accurate. Number 3? Oh boy. I fixed the modulo error unknowingly and reverted the edit from the second submission, but OH BOY WHAT DID I REPLACE THE LINE WITH???
arLen = max(n+k)+3 #array length
Wow. I guess now we’re imploding on basic aspects of Python now. Note that if I had ran the program on the 3 given pretests this would have been caught, but instead I lost 50 more points for failing a pretest that is literally visible in the problem description. You think I’d realize this after seeing “Runtime error on pretest 2”, but nope. For submission 4, what did I think the error was??? I thought print(ans%m) wasn’t working properly. Now excuse me while I go scream at this disaster class in a corner somewhere.
Okay I’m done screaming. Here’s the real kicker behind the Problem D disasterclass:
-
I ended up with 3676 points at the end of the contest, landing me in 668th place with an 1868 ELO performance.
-
1088 of those points came from Problem D.
-
Had I not made the modulo blunder, I would’ve had a successful submission for D 1:18 in the contest, netting me 1376 points.
-
Furthermore, I would not lose an additional 50 points because the hacking attempt I made was one out of desperation to reach a performance level just good enough to reach CM.
-
Thus, the blunder cost me 338 points and had it not happened, I would finish this contest with 4014 points.
-
4014 points would equate to 380th place, an approximate performance of 2004 ELO (1709 base + 82 net gain * 3.6)
-
A 2004 ELO performance would’ve given me about a 34 ELO gain bringing me to 1917 ELO.
-
Even if I made that first wrong submission, had I corrected it on my second attempt, I would still be at 3936 points -> 443rd place -> 1966 ELO performance -> 23 ELO gain -> 1906 ELO -> Still CM
Agony, thy name is 7th grade modular arithmetic.
Round 819
Problems Solved: A, B, C
New Rating: 1870 (-10)
Performance: 1840
EDIT: It turns out Problem F was copied from a past contest, so this entire contest is unrated. At least I didn’t lose rating?
Contests like these are why I was so mad over how rubbish I performed on the previous round. In the previous round, Problem C was a greedy problem where the induction step was the main challenge, and Problem D was a combinatorics problem where my success depended on finding a pattern. Both of these questions played directly into my strengths, so I should’ve been able to reach CM.
For this contest, Problem C was solved mainly due to luck. My solution that involved counting the number of “()” in the sequence was me throwing ideas randomly. I did not even bother trying Problem D because I found Problem E more approachable. D was a graph/tree problem that took me 10 minutes to understand the problem statement, and even after that I had no clue how to begin. E turned out to not be much better as one of the problem tags for this question was fast fourier transform, something I still have no clue of. My attempts at E involved finding the answer for small n values to create some sort of pattern. For 2 to 9, I got [2,4,12,32,100,312,1076,3772]. I suspect there is some sort of recurrence relation here but I could not find it. I have attempted this sort of method of brute forcing small n values to see a pattern before with mixed success, but here I feel this idea may have been a pitfall. I also attempted to find some sort of dp method for E but nothing was found.
With C being a lucky solve, D being a graph problem, and E requiring a technique I have no clue of, this contest was better executed than the previous one. Yes it was worse overall, but my only mistakes were a slow B solve and rushing my first attempt on C. It still hurts though that I’m only 30 20 points away from CM, but with school starting tomorrow (September 7th), it feels so far away.
This blog was posted a week early, mainly due to the fact that there are no more contests coming in this two week period. I am starting classes at SFU again, 6 in fact. You can still expect frequent activity on other Github projects I’m working on as well as the rating post sometime at the end of this month. Alas, my goal of returning to CM by the end of this year is significantly harder now due to fewer contests and having much less time than normal to prepare.
September 8th update
Well, it turns out I’m incompetent when it comes to reading CodeForces schedule, because it turns out there was a contest today. Even better, my classes start later on Thursdays so I conveniently was able to attend today’s round. Let’s see how it went.
Educational Round 135
Problems Solved: A, B, C, D
New Rating: 1808 (-72)
Performance: 1585
On second thought, I’d say it’s just best to end this entry here.
Okay fine, I’ll explain what happened. The contest opened with a strong Problem A-C solve in 30 minutes that had no major errors. Yes, there is a massive issue I’m ignoring here, we’ll discuss that, but first let me how I did Problem D. I approached this question perfectly.
The first thing I noticed is that the input size is much smaller than normal; the number of characters s will be at most 2000. 2000^2 is only 4 million, so an O(n^2) will actually be fast enough. O(n^2) is special because it means that a dp approach is more likely since 2d array representation usually won’t timeout. That said, I tried finding a greedy option first that involved trying to pick the best move for each player in a game. I soon realised that most of my greedy attempts were incredibly scuffed, and that a game with a 2 character string is trivial: if both characters are the same, the game is a draw, else Alice wins. From there, a dp approach can be used to calculate the result for 4-char substrings, 6-char substrings, and so on.
Using an example, consider the string abbcca. The algorithm determines that ab,bc, and ca are wins for Alice, while bb and cc are draws. This info is represented in the array [1,0,1,0,1], where 1 = Alice and 0 = Draw. Now consider the 4 character strings. The first one is abbc, and only the middle 2-char substring bb is a draw. However abbc is not a draw because even though Bob can force bb to be the remaining string, Alice could choose the a from earlier to finish with a string of ba to Bob’s bc. Thus abbc = 1. bbcc however is a draw because if Alice chooses b, Bob copies to get to cc, and if Alice chooses c, Bob copies to get to bb; both of these scenarios play out in a draw. For bcca, similar logic to abbc applies to show this is a win for Alice. This info is stored as [1,0,1]
This leaves the main string abbcca. Note that Alice choosing from the left leaves either a draw or win [0,1], and choosing from the right leaves either a win or draw [1,0]. Since the middle 4 characters lead to a draw, and the end characters are equal, the entire string is a draw. The array notation I used to track this data also helps in simplifying the logic for the program.
Thus concludes my Problem D approach. I even had the right idea for Problem E. You can find the maximum value for using x red peppers and n-x black peppers by first tracking the difference in tastiness between the two for each dish. Then find the total tastiness when using n red peppers, and then swap in black peppers from most to least effective to get the best result for every combination. This part can be done in O(n log n), and each shop query is likely solvable in O(log n) time each by using Euclid’s algorithm to solve each Diophantine equation. Unfortunately, I was running short on time to implement this part, and resorted to a brute force to attempt a hail mary solve. The submission made it past 6 test cases before TLE occurred, so it’s safe to assume I had the right approach.
And then there’s Problem C. Had I not been hacked, my submission would have fully passed the test cases, I would have gained about 30 ELO, and I’d be writing this contest as a storybook ending where I finally return to CM again. I even resubmitted the original solution to confirm this. Alas, I’m now 92 ELO out of CM, and only a miracle can really get me back there before this year ends. (I’d need another Master level performance to make it back, or several CM performances. Both are longshots at best right now.) The cause of this successful hack is due to how Python hashmaps work. Hashmaps are incredibly useful for key value pairs by using additional memory for O(1) lookups. However, this is only possible if the hash function maps keys to the hashmap’s memory in a relatively even distribution. For most datasets this isn’t a problem, but specific key values will cause many hash collisions, which tl;dr, makes the lookup go from O(1) to a worst case O(n). This can make a program slow down to O(n^2), but this is incredibly unlikely for random number sequences. In fact, you’d need a key sequence intentionally designed in a way that makes the hash function map keys all map to the same value to cause an O(n) blowup.
You can probably tell what happened. It turns out the hash function for Python is simple enough that the following code can generate an array of values that can cause such a blowup:
def screwpythonhashtables():
arr = []
mask = (1 << 17) - 1
fill = int((1 << 15) * 1.3 + 1)
arr = []
# arr = [1]*199998
arr += [mask + 2] * 2
x = 6
for i in range(1, fill):
arr += [x] + [x]
x = x * 5 + 1
x = x & mask
arr += [1] * (n - len(arr))
For future contests a possible solution is to run all values used for a hashmap in a self made hash function to generate a more even distribution of values. I’m currently working on such a solution to be added to the Python comp lib, partially because it’s important, and partially because I’m still hurting over this contest. Also, such hashmap hacks also exist in C++, so programming language was never the issue. With school already loading up work on me at a rapid pace, I’ll be lucky if I have the time to join CodeForces contests consistently in these next 4 months, let alone have actual practice time. And to think that a hashmap exploit, the last thing on my mind immediately after that contest, would be why I’m sad now. I think this past excerpt from August is fitting here: Oh, and I haven’t even mentioned this yet:
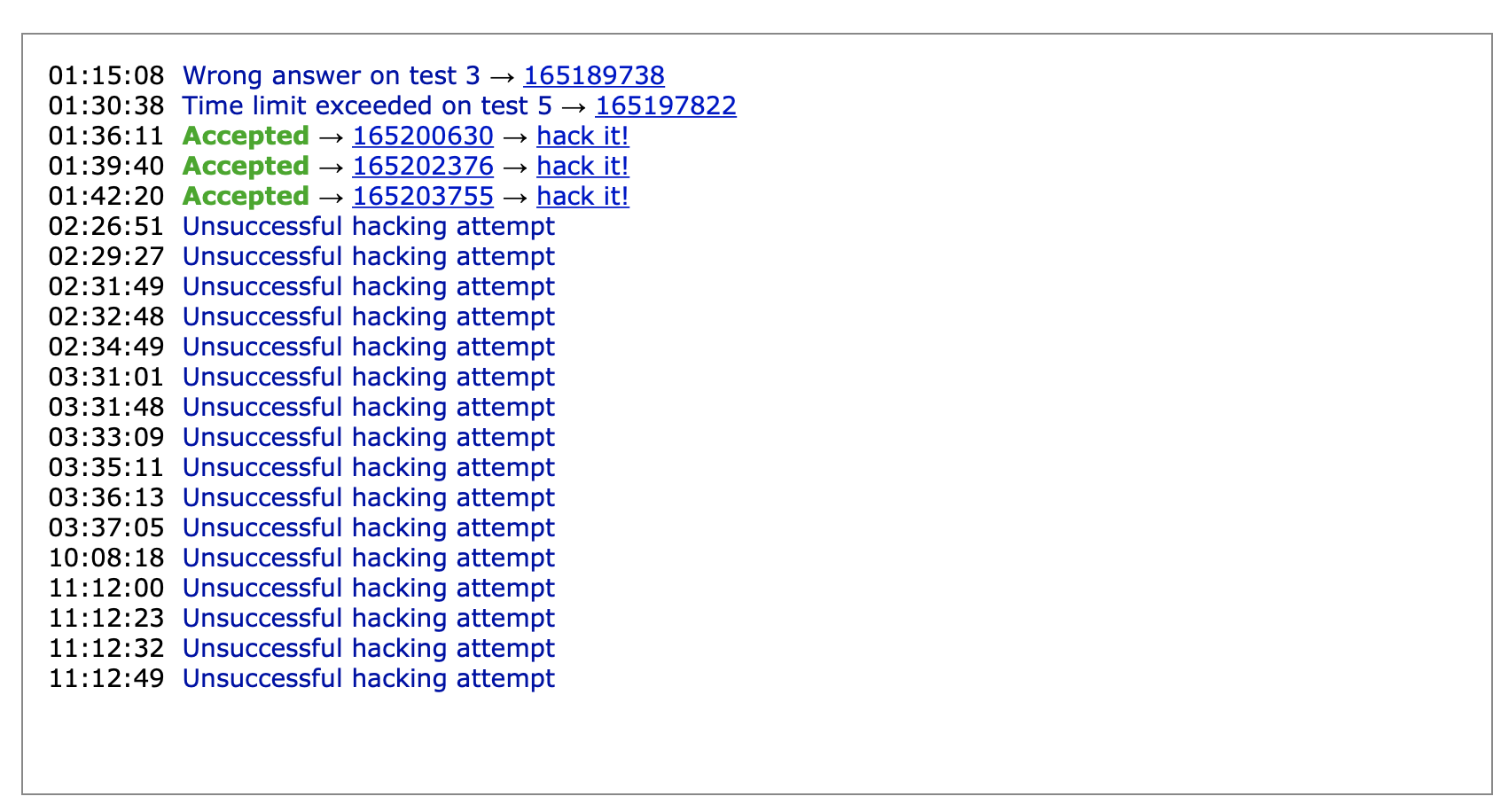
As if the near TLE shenanigans weren’t enough for my blood pressure, a total of **16** attempts from 5 different people were made to break my solution. AND my solution defended all of them successfully. Just about every attempt made was to try and make my solution exceed the time limit, and the closest any of them got was about 882ms. If anyone who tried hacking my solution is reading this, then to you specifically, thank you for trying to hack me, defending all of the hacking attempts actually felt good.
The inverse really is true. Defending a hack makes you feel amazing, while being hacked is about the worst feeling imaginable on CodeForces. As a final note, please do not search or harass the person who hacked me; hacking on CodeForces is an innovative and fair aspect of the contests. If you do hack someone, you deserve the reward of increasing your own rank in the contest, and if you are hacked, then your solution failed a legitimate test case within the constraints of the problem and doesn’t deserve to be correct. That said, this sort of pain is nothing like the rage I felt over Round 818. It’s more of an agonising sadness that tears at you, like finally qualifying for a national sports competition two weeks away, only to get in a car crash hospitalising you long term. It is hyperbole, but unfortunately, it’s been two days since that contest as of writing this, and I don’t think I’ll forget this moment anytime soon.
September 16th-30th
Round 821
Problems Solved: B, D1, A, C
New Rating: 1758 (-50)
Performance: 1606
The link above summarises my thoughts on this contest: a clown show. Excuse my language for a moment, but it needs to be asked:
what in the actual hell was that.
In a contest where I was expected to begin a recovery after losing rating in 3 consecutive agonising contest failures, I proceeded to have such a ridiculous contest that this blog entry is the only way I can explain that I was not trolling. The ordering of the problems solved is intentional; I really solved Problem D1 before Problem A. I’ll ignore the fact that the amount of time I spent thinking on how to solve A is about the same amount of time for bamboo to have a visible growth spurt since fixating on solving A first would’ve made this contest even more of a dumpster fire but there were still MANY execution mistakes in this contest.
Problem B’s first submission was inaccurate as all hell. I somehow thought its output for a test case like 7 1 2 was correct because I forgot some competitors would have no wins.
Not much was really wrong with Problem C except for the fact that I kept overcomplicating the potential solution; it took an agonising amount of time for me to notice the very easy method of making the entire array the same value.
Choosing to try and solve E instead of D2. D2 ended up having 522 solves while E had 18 solves. E was worth much more in points but this was essentially a Hail Mary sort of attempt.
The above choice only makes sense if I was absolutely sure that I had no idea how to progress for D2. Thing is that D2 had a giveaway clue in the constraints being n <= 5000. I should’ve realised this meant a O(n^2) solution could work, meaning dp could be a legit idea. Unsurprisingly, there is a dp solution for D2.
In total there were at least 3 significant errors that cost me in this contest. Even if I did not solve D2 the points lost from burning time on overcomplicating the answers and an idiotic B attempt would have at least prevented yet another 50 ELO loss. I may have been overrated when I first reached CM, but this is now four rated contests in a row where I have lost rating, 3 of which being significant losses. I’m 220 points off of my peak and 142 out from CM. At this point this is less of a knowledge issue, right now I need to regroup myself and stop crapping the bed on questions I should be solving efficiently.
And it’s not like I’m not capable of having a strong contest. Look at this practice contest for Round 820 (Div 3). 6 out of 7 correct with E and F being 1800 and 1900 rated problems respectively. This would’ve been good for 42nd in the live contest for a performance rating of around 2204. This may be clearly overrated but E and F are easily Div 2 D-level problems. I clearly have the capability of doing better than these choke jobs, so to see myself struggling on Problem fricking A is just, how??? I swear if the contest on September 25th ends up being a shitshow I am going to lose it.
Round 822
Problems Solved: A, B, C, D
New Rating: 1770 (+11)
Performance: 1793
Well this is a surprise. I wasn’t even supposed to be in this contest, but due to incredible luck, this contest was 2.5 hours earlier than normal to avoid a scheduling conflict with a contest on CodeChef. Sure, this contest is happening at 5am in my local time, but past experiences make this endurable.
Sure, Problem C was a bit of a mess with it taking 41 minutes due to logic errors in my solution, and the contest as a whole had problems with significantly higher clear rates than normal, but for once, I completed an A-D solve without major issues. My Round 818 performance may be statistically better, but for once, I am recapping a contest where I don’t end up writing an essay ranting on all the blunders I made. Problem D in particular was surprisingly well done with myself finding the idea of using a “back-and-forth path” solution quickly, and it was the main reason I ended up with a positive rating gain since the contest I reached CM. The contest may not have been perfect, but this pretty much sums up my thoughts on it (the image below was made right after the contest, rating changes can slightly fluctuate a few days after the contest):

Hopefully I can continue this momentum into this Sunday’s contest.
Round 823
Problems Solved: A, B, C
New Rating: 1709 (-61)
Performance: 1535

To myself, conglaturations. I was considering making the recap of this contest and several of the other disasters into its own post portraying reaching CM as an ironic “curse”, but there was a chance that it could’ve been quickly outdated since Educational Round 136 and Global Round 22 happen this Thursday and Friday respectively. Had I got Problem B, this would’ve been a peaceful recap where the main focus is myself making the questionable decision to attempt a Problem E with only 5 solves instead of Problem D with 286 solves. In fairness, I did have more of an idea on how to start E, and I actually succeeded in creating a logically sound solution; I just incorrectly estimated its runtime to be O(n log n) when it was actually O(n^1.71).
Now, Problem B. After the contest (and an undisclosed amount of time in the first four stages of grief), I tried figuring out how everything went to pot by recording my analysis of the failed submissions in a semi-structured rant on Discord. The first attempt was me trying to get the absolute error under 10^-6. I decided to be safe by aiming for an abs error under 10^-8, but this caused a TLE for the following reason:
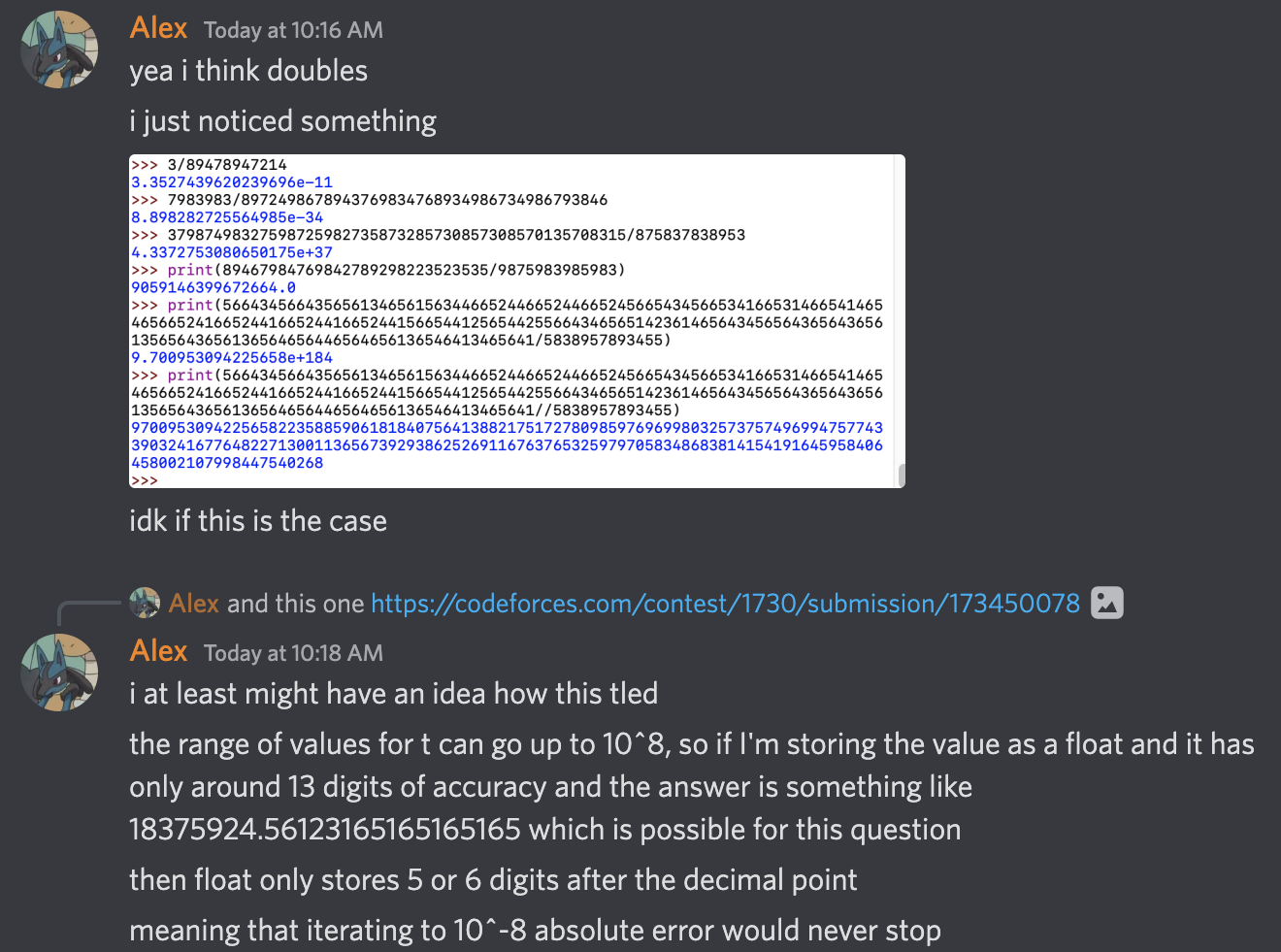
To prevent a TLE in Attempt 2, I forced the binary search to do a specific number of iterations. I tried 20 first, since (1/2)^20 is about 10^(-6) and taking the middle of the two values would likely get me within the relative error of 10^(-6). I knew this had a chance of failure due to it being very borderline, so when it did, I adjusted to 25 iterations, and it passed pretests.
We all know what happened after that. You may also have noticed I completely misunderstood the meaning of relative error:
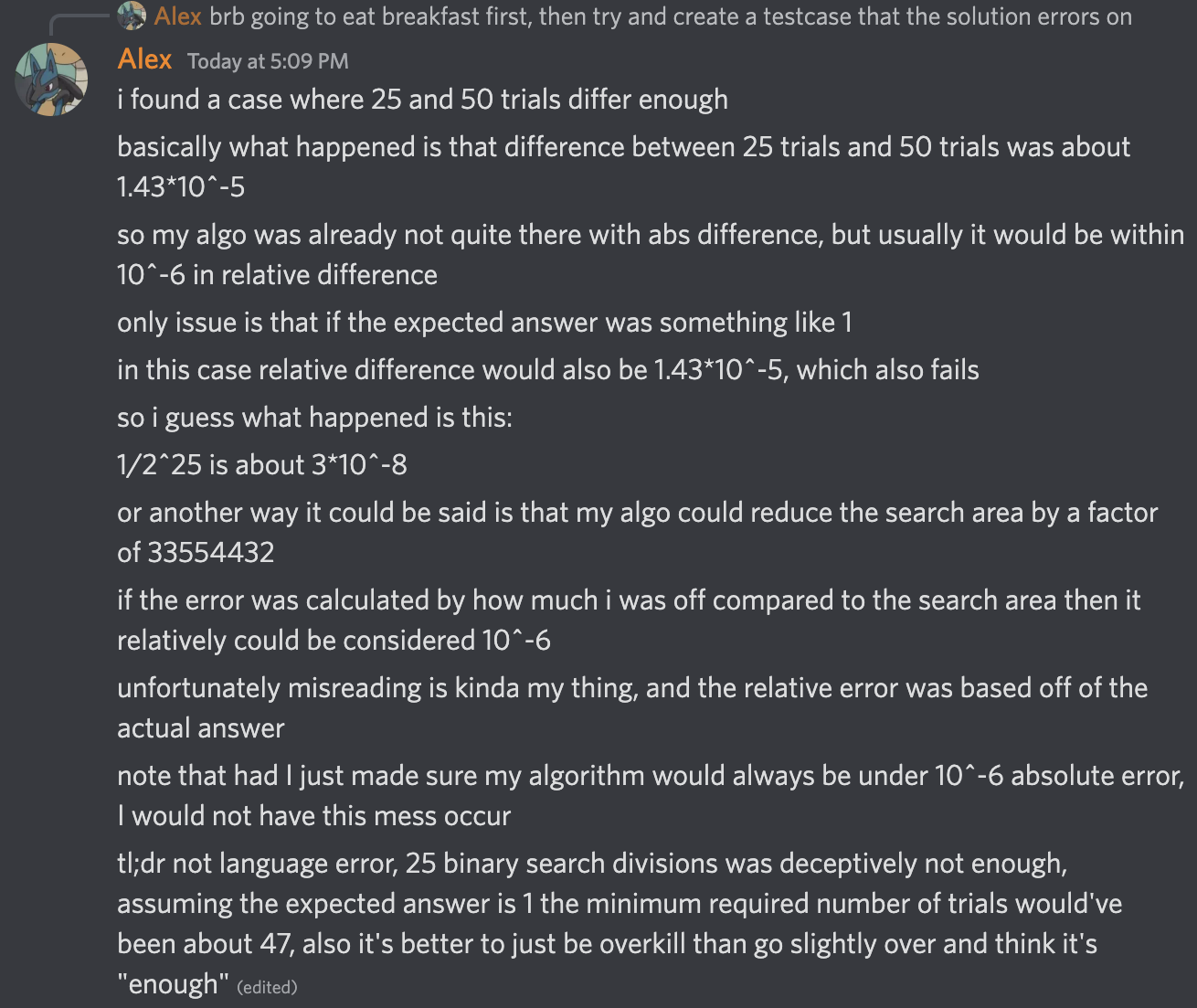
My overall reaction after this contest: Do I even have to say it?
I’m now 272 ELO below my all time peak. The only other time I was over 200 points below my peak was after the “I can’t count to five” contest. Even still, there is no reason for me to quit now. At this point, any contest performance that isn’t an implosion will help in bringing me back up, and even though the previous contests have been trainwrecks, I have still shown I’m capable of doing well. Round 822 went smoothly even though it was at 5am. I still got 4 problems correct in 3 of my last 6 contests, and had I not been hacked, I’d even have made it back to CM after e134. Mean regression is cruel, but at this point, I’m likely below my mean. I may be stuck in this hole, but only an idiot would wallow in self pity instead of finding a way to get out.
Educational Round 136
Problems Solved: A, B, C
New Rating: 1738 (+29)
Performance: 1817
I had a suboptimal initial approach for Problem C, mainly because I really thought I could just OEIS the sequences. I should not be using this as my first approach since it’s pretty much me “hoping” for the sequence to have been created before. Relying on “hope” strategies is usually an easy way to fail since most of the time it’s equal to trying to “cheese” a solution. It could work, but in practice it usually doesn’t. At least I figured out the formula in C using a dp like method. The low constraint for n also means no fancy factorial methods are needed.
From there most of the time I tried to solve Problem D. The first 20 of about 80 minutes were burnt on Problem E since I looked at D, saw it was a tree problem, then quickly assumed E was easier. Turns out that I’m actually decent at tree problems now since I ended up having more progress on D. I properly determined how many nodes are on each level of the tree. Where I got stuck was figuring out which layers to cut, for which I tried to create a dp like idea for, but ran out of time. Even if it was implemented properly I’d probably need a sparse table to get the needed O(1) lookup times for a O(n log n) solution. Still, this was a pretty difficult problem, and I did get A and B very quickly to place myself in the top 1000. Now I just hope Problem B didn’t get hacked because as of writing this, there have been so many hacks for B that for a short time, the CodeForces website literally went down. I’m writing this 100 minutes after the contest and the solve rate for B is still collapsing.
Global Round 22
Problems Solved: A, B, C, D
New Rating: 1809 (+71)
Performance: 2009
Anytime I complete a full A through D solve on a contest is usually a good sign, and this was no exception. The only questionable play was Problem B where solutions kept screwing up because I forgot about the n = 1 edge case. Everything else though was done relatively well. Problem C is a simple game logic puzzle that went about as perfectly as possible. Implementation is not really a challenge for C, but it mainly determines who wins given a current game state.
Problem C Important Observation
The only thing that matters about the values are if they’re even or odd, which means the solution is reliant on how many even/odd values there are at the starting state. Let x = # of even vals and y = # of odd vals. With some basic game simulation you can find that the game result can vary depending on if x is odd or even and on what the value of y % 4 is. This gives 8 possible game states that can have the winner determined manually.Problem D was pretty ugly with how long it took and 2 wrong submissions, but I did solve it.
Thoughts on Problem D’s solution
This problem actually has two independent parts, being to determine what the k value is, and what the original array is. I figured the original array surprisingly easily and my wrong submissions actually came from the wrong k value. The array building method somewhat resembles a DFS except out of each layer only one of the nodes can have children, thus every value will be added in the array. Funny how this is technically a “tree” problem and I yet again solve it without even thinking of it as a tree.I even had time to try Problem F, which was a tactically correct decision since the solve count between E and F was 483 and 344 respectively, not much of a difference. That said, both problems are pretty much out of my current skill level. I ended up running out of time to actually complete a proper implementation of my solution to F, and even if I did fix it properly in time, the solution breaks down on graphs with more than n edges.
Thus concludes another two week span where I ran in 5 contests. It was looking incredibly ugly at first, but I am recovering my rating now and may return to CM in time. SFU courses are still weighing down on me so I’m more focused on outlining the end of year recap post first right now. It also wouldn’t really make sense for someone who barely touched CM to be explaining what each rating means. Maybe for that post I’ll split into parts describing a few rating groups as I actually climb the elo ladder of CodeForces. For now though, this post marks the end of the 3rd quarter of this year where on average I participated in a CodeForces contest once every 4.38 days, or just under 2% of my life in the last 3 months has been in a CodeForces contest. Pretty insane to think about.
Oh, and this contest’s Problem B also had a System Test Armageddon. That makes two contests in a row where Problem B decided to be a troll and cause lots of post contest failures. And this was right after I system failed Problem B in Round 823. What a coincidence.